Weights & Biases Weave - Tracing, Monitoring and Evaluation
What is W&B Weave?
Weights and Biases (W&B) Weave is a framework for tracking, experimenting with, evaluating, deploying, and improving LLM-based applications. Designed for flexibility and scalability, Weave supports every stage of your LLM application development workflow.
W&B Weave's integration with LiteLLM enables you to trace, monitor and debug your LLM applications. It enables you to easily evaluate your AI systems with the flexibility of LiteLLM.
Get started with just 2 lines of code and track your LiteLLM calls with W&B Weave. Learn more about W&B Weave here.
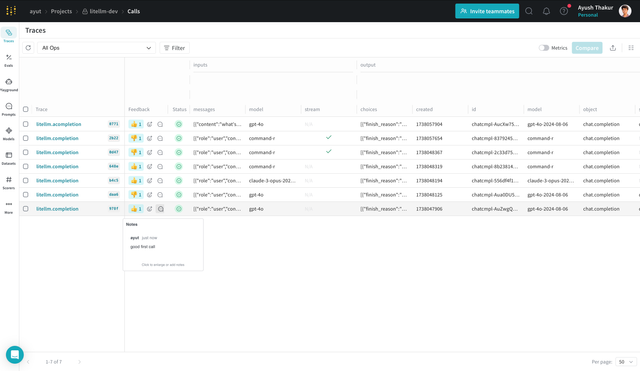
With the W&B Weave integration, you can:
- Look at the inputs and outputs made to different LLM vendors/models using LiteLLM
- Look at the cost, token usage and latency of the calls made
- Give human feedback using emojis and notes
- Debug your LLM applications by looking at the traces
- Compare different runs and models
- And more!
Quick Start
Install W&B Weave
pip install weave
Use just 2 lines of code, to instantly log your responses across all providers with Weave.
import weave
weave_client = weave.init("my-llm-application")
You will be asked to set your W&B API key for authentication. Get your free API key here.
Once done, you can use LiteLLM as usual.
import litellm
import os
# Set your LLM provider's API key
os.environ["OPENAI_API_KEY"] = ""
# Call LiteLLM with the model you want to use
messages = [
{"role": "user", "content": "What is the meaning of life?"}
]
response = litellm.completion(model="gpt-4o", messages=messages)
print(response)
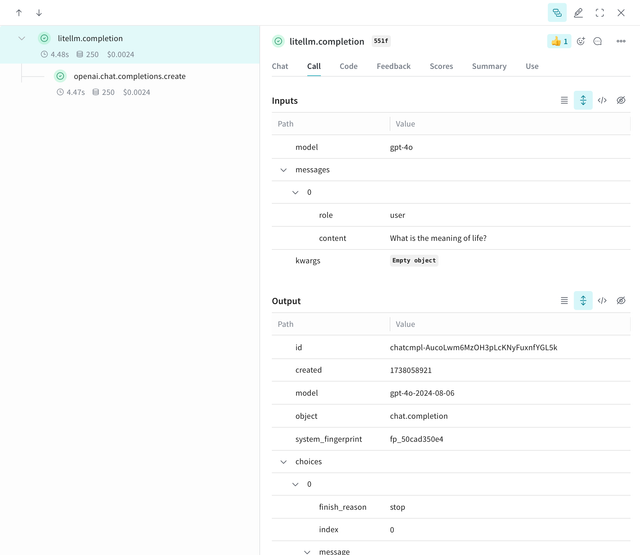
You will get a Weave URL in the stdout. Open it up to see the trace, cost, token usage, and more!
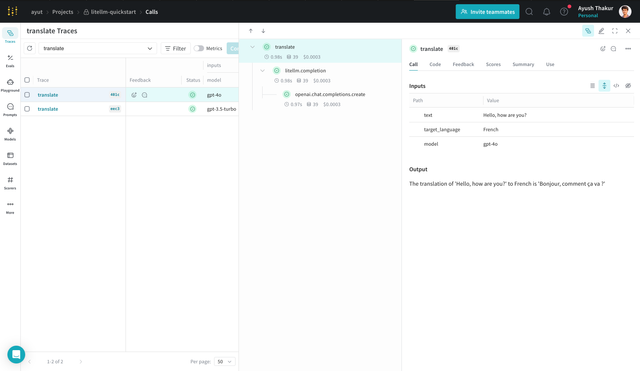
Building a simple LLM application
Now let's use LiteLLM and W&B Weave to build a simple LLM application to translate text from source language to target language.
The function translate takes in a text and target language, and returns the translated text using the model of your choice. Note that the translate function is decorated with weave.op(). This is how W&B Weave knows that this function is a part of your application and will be traced when called along with the inputs to the function and the output(s) from the function.
Since the underlying LiteLLM calls are automatically traced, you can see a nested trace of the LiteLLM call(s) made with details like the model, cost, token usage, etc.
@weave.op()
def translate(text: str, target_language: str, model: str) -> str:
response = litellm.completion(
model=model,
messages=[
{"role": "user", "content": f"Translate '{text}' to {target_language}"}
],
)
return response.choices[0].message.content
print(translate("Hello, how are you?", "French", "gpt-4o"))